
L'IA du point de vue de l'investisseur.
Partie I : L'IA est-elle une bulle ? Les analystes de l'IA sont-ils fous ?
L'IA est omniprésente ces jours-ci et, dans une certaine mesure, elle fait l'objet d'un battage médiatique. Même le nombre de posts LinkedIn sur l'IA est actuellement en pleine effervescence.
Toutefois, contrairement à la bulle SPAC, Weed ou Meme, l'engouement pour l'IA est étayé par de véritables investissements : Meta construit actuellement un centre de données de la taille de Manhattan. Et bien qu'il puisse y avoir une certaine circularité dans les engagements d'OpenAI, de Nvidia et d'Oracle, la plupart des investissements sont en effet soutenus par des flux de trésorerie réels chez la plupart des grands acteurs de la technologie.
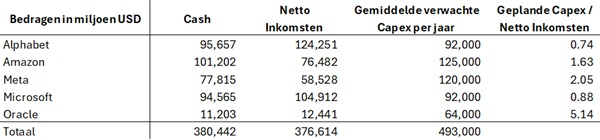
Seuls les investissements d'Oracle font sourciller, les investissements prévus semblant très élevés par rapport au niveau actuel des revenus...

Quant aux valorisations, elles sont évidemment élevées. Par exemple, Nvidia est cotée à un cours/bénéfice prévisionnel de 38,4 fois. Et ce, alors que le modèle de revenus des grands acteurs de l'IA reste quelque peu problématique. Mais nous reviendrons sur ce point plus tard dans la semaine, dans un autre article. Néanmoins, nous ne suivons pas les titres les plus spectaculaires: nous ne qualifierions pas (encore ?) les valorisations actuelles d'insensées : Au plus fort de la bulle Internet en 1999, Microsoft se négociait à un ratio cours/bénéfice de 71 fois, et Cisco se négociait même à 171 fois ses bénéfices.
L'IA fait donc l'objet d'un certain engouement. Mais nous ne pouvons pas encore parler d'une véritable bulle.
Partie II : Divergence ou gagnant ?
La frénésie actuelle de construction et la bataille pour des centres de données toujours plus grands peuvent donner l'impression que le marché de l'IA est en train de devenir un modèle où le gagnant prend tout. Un peu comme Google qui détient une part de marché de 90 % sur les recherches. Les effets de réseau garantissent que chaque recherche ultérieure est meilleure.
Avec l'IA, cependant, ce n'est pas le cas pour l'instant : comme Deepseek l'a démontré l'année dernière, il est en effet possible de créer un modèle avec un budget relativement limité qui n'est pas très en retard par rapport aux leaders de l'industrie. De plus, il y a également - certainement en provenance de Chine - une forte poussée vers les modèles open source. Ainsi, il existe déjà plus de 2 millions de modèles d'IA différents.
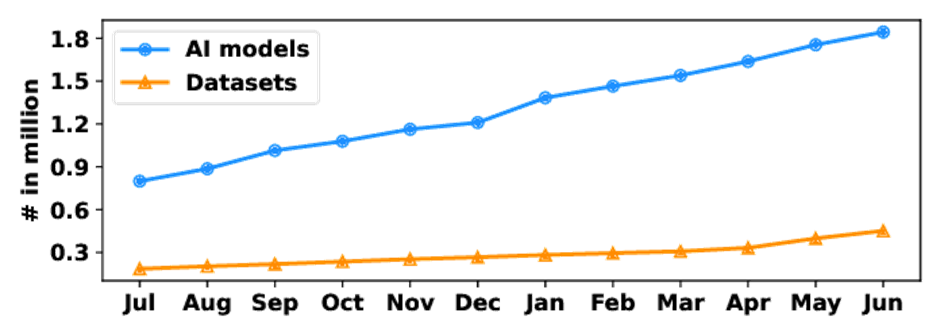
La bataille de l'IA n'en est qu'à ses débuts. L'avenir nous le dira. Mais il est frappant de constater que, d'une part, les investissements dans les centres de données sont importants - comme on pourrait s'y attendre dans un marché où tout le monde gagne - alors que, d'autre part, le nombre de modèles et leur utilisation suggèrent plutôt le contraire. En outre, OpenAI , qui est le premier sur le marché, perd actuellement de solides parts de marché...
Au-delà du ChatGPT
En matière d'IA, la presse populaire parle surtout d'OpenAI. En réalité, OpenAI reste populaire auprès des consommateurs ordinaires, mais l'entreprise de Sam Altman perd du terrain sur le marché professionnel.
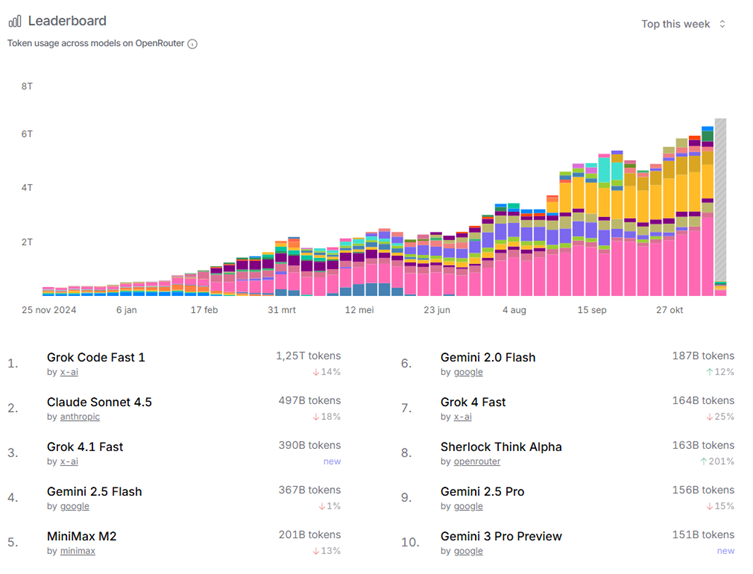
Alors qu'en tant que consommateur, vous avez votre assistant personnel d'IA dans votre poche pour un abonnement mensuel pratiquement illimité, un professionnel paie en fonction de son utilisation, avec un prix par "jeton" utilisé. Les plateformes comme OpenRouter permettent un passage très souple d'un modèle à l'autre et constituent donc un indicateur utile pour voir quels sont les modèles les plus utilisés. Vous trouverez ci-dessous le tableau des jetons utilisés dans les différents modèles.
Les offres promotionnelles et les versions gratuites ont permis à Grok d'Elon Musk de prendre 2 places sur le podium. Ensuite, Gemini et Claude d'Anthropic tirent leur épingle du jeu. ChatGPT n'a plus un seul modèle dans le top 10... Y a-t-il aussi une malédiction des gagnants avec les modèles d'IA ?
Partie III : Dépassement de capacité
Dans un article précédent, nous avons parlé des énormes investissements dans l'IA. Dans les années à venir, les "big 5" de la tech dépenseront jusqu'à plus de 500 milliards par an en capex pour construire des centres de données. Ce sont des sommes que nous avons du mal à imaginer. À titre de référence, c'est à peu près autant que l'ensemble du secteur agricole européen. Ou environ 20 fois le chiffre d'affaires annuel mondial de McDonalds, si cela peut être concret....

On peut se demander si cela ne va pas entraîner une surcapacité massive à long terme. D'autant plus qu'un grand nombre de "petits modèles" dotés d'une puissance de traitement plus limitée parviennent tout de même à atteindre 80 % du niveau des meilleurs modèles. Et qu'ils peuvent être "suffisamment bons" pour de nombreuses tâches.
Personnellement, nous avons un peu l'impression que le boom des câbles sous-marins s'est produit au début des années 2000. L'internet était sur le point de conquérir le monde, et une énorme quantité de câbles internet a été construite à l'étranger. En fin de compte, la plupart des investissements se sont retrouvés à proximité des câbles, dans les profondeurs de l'eau. Mais l'infrastructure construite à l'époque a permis à l'internet de se développer au cours des décennies suivantes pour devenir ce qu'il est aujourd'hui.
Les acteurs de l'IA d'aujourd'hui sont-ils les nouvelles entreprises de câbles sous-marins ? La frénésie de construction entraînera-t-elle bientôt une surcapacité et une chute des prix ? Dans ce cas, en tant qu'investisseur, il vaut mieux rester sur la touche. Mais en tant qu'utilisateur, une telle situation peut être très amusante. Qu'en pensez-vous ?

Partie IV : L'IA comme sélectionneur de titres
Il existe plus de 50 000 sociétés cotées en bourse dans le monde. En tant qu'analyste, il est donc illusoire de vouloir les connaître toutes en détail. C'est notamment pour cette raison que les modèles informatiques sont bien établis depuis des décennies pour la sélection des titres : des ratios et des mesures d'évaluation sont calculés sur la base des chiffres financiers et un premier filtrage est effectué.
La liste encore longue des entreprises qui survivent à ce filtrage est signalée comme "potentiellement intéressante". L'analyste commence alors à faire ses devoirs. Comme le dit Warren Buffett : vous commencez par les entreprises qui portent la lettre A, puis celles qui commencent par un B, et ainsi de suite....
L'inconvénient de cette approche, d'une part, est que les informations les plus intéressantes ne se trouvent souvent pas dans les chiffres eux-mêmes. Mais plutôt dans les notes, les perspectives, les orientations formulées par la direction de l'entreprise et les informations qui replacent les chiffres dans leur contexte. Jusqu'à récemment, cela ne pouvait se faire qu'en lisant attentivement tous les documents de l'entreprise avec la discipline nécessaire. Et la décision la plus courante prise dans une analyse d'actions est de ne pas investir en fin de compte : pour chaque entreprise qui est finalement considérée comme digne d'être investie, un analyste en examine souvent dix pour lesquelles la conclusion est "non".
C'est là qu'interviennent les grands modèles linguistiques (LLM) : ils sont tout simplement conçus pour examiner de grandes quantités de texte et les résumer. Ils permettent également de rechercher des incohérences, des changements d'un trimestre à l'autre, etc. Ainsi, en utilisant intelligemment des analystes IA (bien formés), l'aspect filtrage peut être étendu et permettre de filtrer du texte en plus des chiffres. De cette manière, on peut déjà commencer à repérer les "entreprises potentiellement les plus intéressantes".
Bien entendu, il est impératif que l'analyste humain fasse ses devoirs avec les connaissances et la discipline nécessaires. Demander simplement à ChatGPT quel serait un investissement intéressant et suivre aveuglément ce conseil n'est évidemment pas une bonne idée. En revanche, l'utilisation d'une IA bien entraînée pour filtrer les documents et rendre ainsi la liste des entreprises que vous, en tant qu'analyste, approfondissez aussi pertinente et intéressante que possible, aide les analystes d'actions à augmenter leur taux de réussite.

Partie V : Comment l'argent de la Flandre occidentale a posé la pierre angulaire de la révolution de l'IA.
En 1990, Ray Kurzweil avait prédit que, si la puissance de calcul continuait à s'améliorer au même rythme, nous atteindrions l'intelligence artificielle générale (AGI) en 2029. Ce qui est frappant, c'est qu'en 2025, nous sommes toujours en bonne voie pour atteindre cet objectif. Il suffit donc de patienter encore quelques années ! À cet égard, il n'est pas surprenant que les grands acteurs de la technologie consacrent des budgets importants à l'IA : nous pouvons presque toucher le Saint Graal.

Pour les investisseurs de Flandre occidentale qui ont une bonne mémoire, le nom de Kurzweil peut encore faire tilt. En 1998, en pleine bulle Internet, sa société, Kurzweil Applied Intelligence, a été rachetée pour 53 millions de dollars par... Lernout & Houspie.
Lorsque L&H a fait faillite, l'homme s'est retrouvé avec une belle somme d'argent et une grande passion pour l'IA-avant-la-lettre. Il a utilisé son temps à bon escient, en fondant le "Singularity Summit" en 2006, avec Peter Thiel et d'autres. C'est lors de ce Singularity Summit que Demis Hassabis, le fondateur de Deep Mind, a rencontré Peter Thiel. Il a ainsi réussi à obtenir le financement nécessaire pour sa petite entreprise d'IA auprès de Peter Thiel et... d'Elon Musk, entre autres.
Deep Mind a été racheté par Google en 2014 pour la modique somme de 500 millions de dollars. Bien qu'il ait réussi à s'imposer au box-office, Elon Musk ne s'est pas amusé de cette situation. Il a tenté de faire une nouvelle contre-offre, qui a été rejetée par Deep Mind. En guise de contre-attaque, il a alors créé une nouvelle entreprise visant à développer l'IA en tant que logiciel libre. Elle s'appelle... OpenAI. Le reste appartient à l'histoire (tumultueuse).
Mais avec la nuance et la liberté éditoriale nécessaires, nous pouvons donc dire (en gros) que l'investisseur L&H de Flandre occidentale a fait partie du berceau de ce qui est devenu la vague actuelle de l'IA...
Auteurs : Jens Verbrugge, Tibo Dewispelaere, Wouter Verlinden